A Dataset Perspective on Offline Reinforcement Learning
Abstract
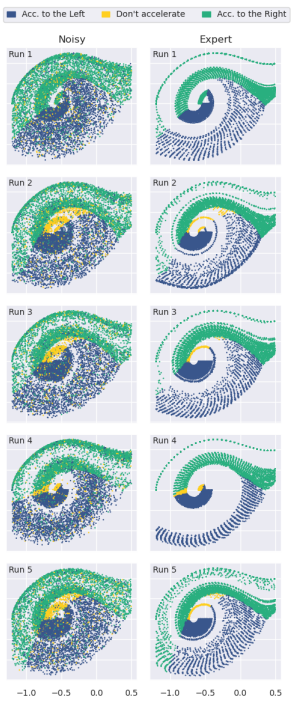
The application of Reinforcement Learning (RL) in real world environments can be expensive or risky due to sub-optimal policies during training. In Offline RL, this problem is avoided since interactions with an environment are prohibited. Policies are learned from a given dataset, which solely determines their performance. Despite this fact, how dataset characteristics influence Offline RL algorithms is still hardly investigated. The dataset characteristics are determined by the behavioral policy that samples this dataset. Therefore, we define characteristics of behavioral policies as exploratory for yielding high expected information in their interaction with the Markov Decision Process (MDP) and as exploitative for having high expected return. We implement two corresponding empirical measures for the datasets sampled by the behavioral policy in deterministic MDPs. The first empirical measure SACo is defined by the normalized unique state-action pairs and captures exploration. The second empirical measure TQ is defined by the normalized average trajectory return and captures exploitation. Empirical evaluations show the effectiveness of TQ and SACo. In large-scale experiments using our proposed measures, we show that the unconstrained off-policy Deep Q-Network family requires datasets with high SACo to find a good policy. Furthermore, experiments show that policy constraint algorithms perform well on datasets with high TQ and SACo. Finally, the experiments show, that purely dataset-constrained Behavioral Cloning performs competitively to the best Offline RL algorithms for datasets with high TQ.